

是函数,Γ(n/2)称为伽马函数。
Γ函数Γ(x)=∫(0→∞)exp(-t)t^(x-1)dt是个超越函数。
因为满足Γ(x)=xΓ(x-1),所以也被当作是阶乘的推广。
Γ(x-1)=x!
Γ,是第三个希腊字母的大写形式(小写γ),读音GAMA。
伽玛函数是阶乘的推广。通过分部积分的方法,容易证明这个函数具有如下的递归性质。
Γ(x+1)=xΓ(x)
由此可以推导出,对于任意的自然数n
Γ(n)=(n−1)!
由于伽玛函数在整个实数轴上都有定义,于是可以看做阶乘概念在实数集上的延拓。
Γ(x)=∫0+∞tx−1e−tdt。
可以形象理解为用一个伽马刀,对x动了一刀,于是指数为x-1,动完刀需要扶着梯子(-t)才能走下来。
这样,就记住了关键的tx−1,−tt^{x-1},-ttx−1,−t.
性质:
$\Gamma(x+1)=x\Gamma(x)$。
$\Gamma(x)>0,任意x\in(0,+\infty)$。
$\Gamma(1)=1$
用到概率论中的计算形式是:
令t=u2,dt=2udut=u^2,dt=2udut=u2,dt=2udu。
gamma函数1/4能算出来吗
随机变量取一切可能值的概率的规律称为概率分布(probabilitydistribution),简称为分布。
表示分布最常用的方法是直方图(histogram),这种图用于展示各个值出现的频数或概率。
频数指的是数据集中的一个值出现的次数。
概率就是频数除以样本数量n。
用表示概率的直方图称为概率质量函数(ProbabilityMassFunction,PMF)。
常见分布根据变量类型可分为离散型分布和连续型分布。
离散型变量指变量值可以按一定顺序一一列举,通常以整数位取值的变量。
连续型变量是指在连续区间取值,例如质量、长度、面积、体积、寿命、距离等就是连续型变量。
现在试想一下连续变量观测值的直方图;如想其纵坐标为相对频数,那么所有这些矩形条的高度和为1,那么完全可以重新设置量纲,例这些矩形条的面积为1,如果不断增加观测值,并不断增加直方图的矩形条的数目,这些直方图就会越来越像一条光滑曲线,其下面的面积和为1,这种曲线就是概率密度函数(probabilitydensityfunction,pdf),简称为密度函数或密度。
常用离散型分布有:二项分布、几何分布、超几何分布、负二项分布和泊松分布等。
常用连续型分布有:正态分布、卡方分布、指数分布、F分布、伽马分布、t分布、均匀分布、贝塔分布、柯西分布、对数正态分布、Logistic分布、WilcoxonsignedRank分布、Weibull分布,WilcoxonRankSum分布、多元正态分布。
分布族谱:
基于每次的实验有两个可能结果的重复独立伯努利(Bernoulli)试验。
伯努利试验是单次随机试验,只有"成功(值为1)"或"失败(值为0)"这两种结果,是由瑞士科学家雅各布·伯努利(1654-1705)提出来的。
n为实验总次数,k是成功的次数,p是成功概率:
P(X=k)=C_nkpk(1-p)^{n-k}。
典型为掷色子
每次试验不止有两种可能,而是有k种结果;且。
超几何分布就是不放回的伯努利试验;
在抽样调查的实践中,一般不会重复调查同一个体,这相当于不放回抽样,所以应该用超几何分布描述;
但是在一个很大的群体中抽样时放不放回差异很小,但是二项分布计算更简单所以会用二项分布描述。

R语言中与超几何分布有关的函数为phyper,dhyper,rhyper,qhyper。
在一批产品里,一共有N件产品,其中有M件次品,那么当我们任何取n件产品,其中恰有X件次品的概率P就可以按归照下面的公式进行计算:
Bernoulli试验独立地重复进行,一直到出现有功能出现时停止试剂,则试验失败的次数服从一个参数为p的几何分布。
伯努利试验独立地重复进行,一直到出现k次成功时停止试验,则试验失败的次数服从一个参数为(k,p)的负二项分布。
其中:
k是失败的次数,为自变量,取值范围为0,1,2,3,...
r是成功的次数,为固定值。当r=1时,负二项分布退化为几何分布。
p是伯努利试验成功的概率,失败概率则为1-p。
泊松概率分布描述的是在某段时间或某个空间内发生随机事件次数的概率,简而言之就是:根据过去某个随机事件在某段时间或某个空间内发生的平均次数,预测该随机事件在未来同样长的时间或同样大的空间内发生k次的概率。
由于泊松分布适用于描述某段时间(或某个空间)内随机事件发生的次数,因此它常用于预测某些事件的发生。例如:某家医院在一定时间内到达的人数;某段时间内DNA序列的变异数。

其中:
λ是过去某段时间或某个空间内随机事件发生的平均次数。
e=2.71828...,是自然常数
k的取值为0,1,2,3,4,...
k!=kx(k-1)x(k-2)x...x2x1,是k的阶乘。
参数统计学的理论核心。正态分布像一只倒扣的钟。两头低,中间高,左右对称。大部分数据集中在平均值,小部分在两端,因此人们又经常称之为钟形曲线。
正态分布笔记参考
三个特征:
shapiro.test()函数可进行Shapiro-Wilk正态分布检验,用来检验是否数据符合正态分布,类似于线性回归的方法一样,是检验其于回归曲线的残差。
伽玛分布与卡方分布和指数分布有关,卡方分布与指数分布可以视为一种特殊的伽玛分布。

【许多随机变量,例如计算机使用寿命的长度,假定仅取非负值,这种类型数据的相对频率分布通过用Γ型密度函数建模。】
alpha(一般为整数)代表一件事发生的次数;beta代表它发生一次的概率(或者叫速率)。那么gamma分布就代表这么一件事发生alpha次所需要时间的分布。
X∼Gamma(α,λ)
指数分布解决的问题是【“要等到一个随机事件发生,需要经历多久时间”】,伽玛分布解决的问题是“要等到n个随机事件都发生,需要经历多久时间”。
所以,伽玛分布可以看作是n个指数分布的独立随机变量的加总,即,n个Exponential(λ)randomvariables--->Gamma(n,λ)。
alpha代表上述的n,当alpha=1时,伽马分布就变成了指数分布:
卡方分布是由正态分布推导出来的分布,它的定义为,n个独立标准正态变量的平方和称为有n个自由度的χ2分布,记为χ2(n),χ2(n)的总体均值为n,总体方差为2n。
以特定概率分布为某种情况建模时,事物长期结果较为稳定,能够清晰进行把握。但是期望与事实存在差异怎么办?偏差是正常的小幅度波动?还是建模错误?此时,利用卡方分布分析结果,排除可疑结果。
【事实与期望不符合情况下使用卡方分布进行检验】
【常规事件中出现非常规现象,如何检查问题所在的情况下使用卡方分布】
【它广泛的运用于检测数学模型是否适合所得的数据,以及数据间的相关性。数据并不需要呈正态分布】
Γ.表示的是一个gamma函数,它是整数k的封闭形式。
“t”,是伟大的Fisher为之取的名字。
Fisher最早将这一分布命名为“Student'sdistribution”,并以“t”为之标记。
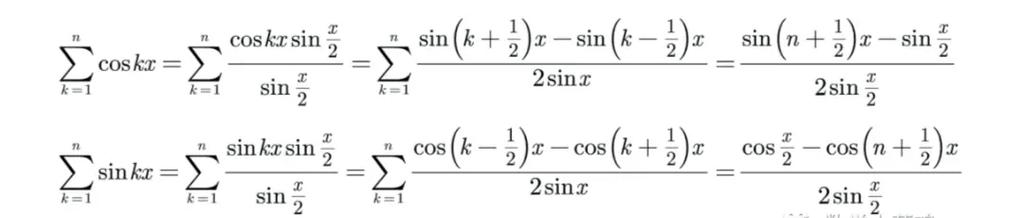
Student,则是WilliamSealyGosset(戈塞特)的笔名。
他当年在爱尔兰都柏林的一家酒厂工作,设计了一种后来被称为t检验的方法来评价酒的质量。
我们平常说的t分布,都是指小样本的分布。但是,随着样本量n/自由度的增加,t分布越来越接近正态分布。正态分布,可以看做只是t分布的一个特例而已。
所以,t分布在大小样本中都是通用的。相对于正态分布,t分布额外多了一个参数,自由度。
【应用在当对呈正态分布的母群体的均值进行估计或者当母群体的标准差是未知的但却又需要估计时】
自由度1~10,t分布为绿色,蓝色为正态分布,t分布也是钟形曲线,但是更宽更厚有尾巴。自由度(希腊字母V,读作“纽”)越大,分布越是接近正态分布。
Gam(x)为伽马函数
研究A、B、C三种不同学校学生的阅读理解成绩找到一种解决的办法,有人可能会以为,只要多次使用Z检验或t检验,比较成对比较学校(或条件)即可。但是我们不会这样来处理。因为Z检验或t检验有其局限性:
(1)比较的组合次数增多,上例需要3次,如果研究10个学校,需要45个。
(2)降低可靠程度,如果我们做两次检验,每次都为0.05的显著性水平,那么不犯Ⅰ型错误的概率就变为0.95×0.95=0.90。
此时犯Ⅰ型错误的概率则为1-0.90=0.10,即至少犯一次Ⅰ型错误的概率翻了一倍。
若做10次检验的话,至少犯一次Ⅰ型错误的概率将上升到0.40(1-0.952),而10次检验结论中都正确的概率只有60%。
所以说采用Z检验或t检验随着均数个数的增加,其组合次数增多,从而降低了统计推论可靠性的概率,增大了犯错误的概率。
【F-分布被广泛应用于似然比率检验,特别是方差分析ANOVA中】
有两个独立的正态分布N(μ1,σ12)和N(μ2,σ22).如果我们对这两个总体进行抽样,获得的样本方差为s12和s22,那么它们遵循F分布:
rbinom(n,size,prob)二项分布。
rgeom(n,prob)几何分布
rhyper(nn,m,n,k)超几何分布。
rlogis(n,location=0,scale=1)logistic分布。
rlnorm(n,meanlog=0,sdlog=1)对数正态。
rnbinom(n,size,prob)负二项分布。
rnorm(n,mean=0,sd=1)高斯(正态)分布。
rexp(n,rate=1)指数分布
rgamma(n,shape,scale=1)γ分布。
rpois(n,lambda)Poisson分布。
rweibull(n,shape,scale=1)Weibull分布。
rcauchy(n,location=0,scale=1)Cauchy分布。
rbeta(n,shape1,shape2)β分布。
rt(n,df)t分布
rf(n,df1,df2)F分布
rchisq(n,df)χ2分布
runif(n,min=0,max=1)均匀分布。
rwilcox(nn,m,n),rsignrank(nn,n)Wilcoxon分布。
自由度
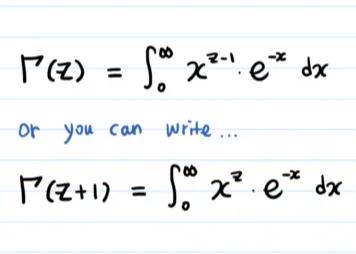
中心极限定理
方差分析



")




还没有评论,来说两句吧...