

网站在提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫做TopN推荐,TopN推荐的预测准确率一般通过召回率和精确率来度量。
在介绍召回率和精确率之前,首先要了解一下混淆矩阵:
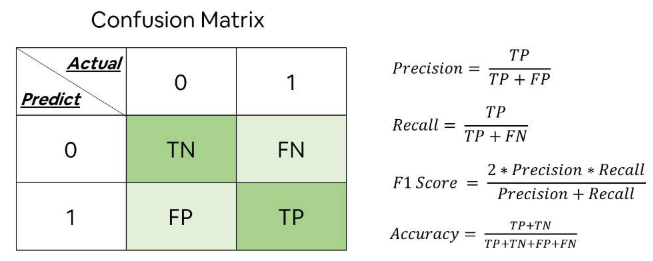
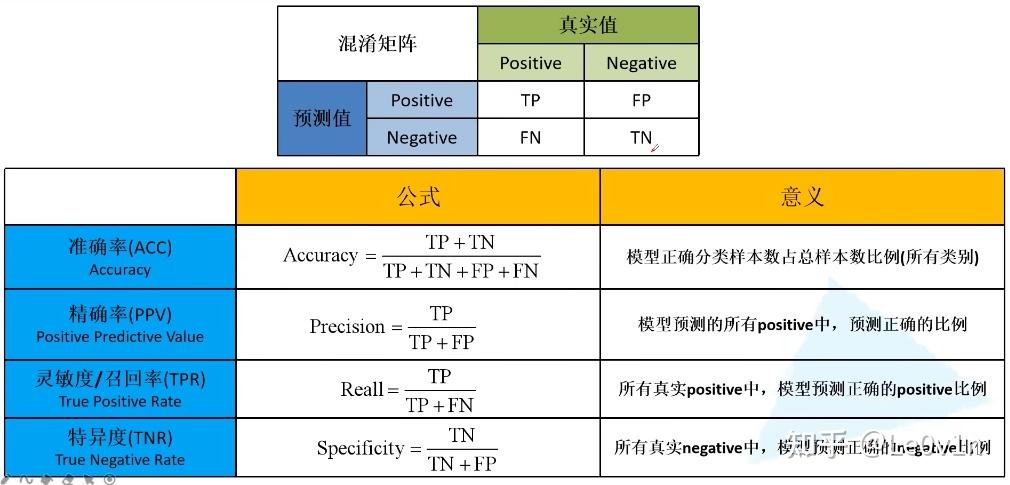
TP(truepositive):表示样本的真实类别为正,最后预测得到的结果也为正;
FP(falsepositive):表示样本的真实类别为负,最后预测得到的结果却为正;
FN(falsenegative):表示样本的真实类别为正,最后预测得到的结果却为负;
TN(truenegative):表示样本的真实类别为负,最后预测得到的结果也为负。
则召回率和精确率分别用混淆矩阵计算如下:两者取值在0和1之间,数值越接近1,召回率或精确率就越高。
通俗来讲,精确率就是说检索出的信息有多少是用户真正感兴趣的;召回率是指用户真正感兴趣的信息有多少被我们预测到了。
要了解AUC,首先要知道什么是ROC曲线。ROC即receiveroperatingcharacteristiccurve受试者操作特征,它源于二战雷达信号分析技术。
ROC曲线绘制:分别计算模型结果的FPR与TPR,然后将TPR作为纵坐标,TPR作为横坐标作图,便可得到ROC曲线,ROC曲线上的每一个点对应一个阈值。
其中,TPR(真正例率):,指的是模型预测的正确正例占所有正例的比例,等同于召回率,可以理解为正例的灵敏度,TPR越大,则预测的正例中正例占比越高;FPR(假负例率):,指的是模型预测的错误反例占所有预测反例的比例,等同于反例预测的错误率,也可以理解为模型对负例的特异度,FPR也可以用公式(1-TNR)来表示。
FPR越大,则预测的正例中反例越多。
AUC:AUC的定义是ROC曲线下的面积,它表示的是随机抽取一对正负样本,把正样本预测为1的概率大于把负样本预测为1的概率的概率。
ROC曲线一般都会处于0.5-1之间,所以AUC一般是不会低于0.5的,0.5为随机预测的AUC。
AUC越大,反映出正样本的预测结果更加靠前,推荐的样本更能符合用户的喜好。
AUC的计算:
法一:按照AUC的含义,计算正例分数大于反例分数的概率,但该方法计算比较复杂,效率不高。
法二:该方法该方法为方法一的进阶版本,首先rank项就是样本按照score值从小到大升序排序,然后只对正样本的序号相加,然后减去正样本在正样本之前的数,结果便是正样本大于负样本的数,然后再除于总的样本数得到的便是AUC值。
它的直观理解就是:rank项是小于该样本分值的样本数;是等差数列之和,即将所有正样本排序之和相加;分子代表的就是将所有小于某正样本的个数去掉,得到的便是小于该正样本的负样本数;是所有正负样本两两排序的数之和;最终得到正样本排在负样本之前的概率值。
精确率和召回率都只能衡量检索性能的一个方面,最理想的情况肯定是精确率和召回率都比较高。
但通常精确率和召回率是此消彼长的,如果我们设定一个阈值,在这个阈值之上的学习器认为是正样本,阈值之下的学习器认为是负样本。
可以想象到的是,当阈值很高时,预测为正样本的是分类器最有把握的一批样本,此时精确率往往很高,但是召回率一般较低。
相反,当阈值很低时,分类器把很多拿不准的样本都预测为了正样本,此时召回率很高,但是精确率却往往偏低。
当我们想提高召回率的时候,肯定会影响精确率,所以可以把精确率看做是召回率的函数,即:,也就是随着召回率从0到1,精确率的变化情况。
那么就可以对函数在上进行积分,也就是计算PR曲线下的面积,得到AP计算公式如下:其中表示第k个文档是否相关,若相关则为1,否则为0,表示前k个文档的精确率。
AP的计算方式可以简单的认为是:其中表示相关文档的总个数,表示,结果列表从前往后看,第r个相关文档在列表中的位置。
比如,有三个相关文档,位置分别为1、3、6,那么AveP=1/3×(1/1+2/3+3/6)。
通常会用多个查询语句来衡量检索系统的性能,所以应该对多个查询语句的AveP求均值即Meanaverageprecision(MAP),公式:
NDCG常用于作为对排序的评价指标,当我们通过模型得出某些元素的排序的时候,便可以通过NDCG来测评这个排序的准确度。
NDCG首先要从CG(cumulativegain,累计增益)说起,CG可以用于评价基于打分/评分的个性推荐系统。假设我们推荐个物品,这个推荐列表的计算公式如下:其中表示第个物品的相关性或者评分。
CG没有考虑推荐的次序,在此基础之后我们引入对物品顺序的考虑,就有了DCG(discountedCG),折扣累积增益。
公式如下:而DCG没有考虑到推荐列表和每个检索中真正有效结果个数,所以最后我们引入NDCG(normalizeddiscountedCG),顾名思义就是标准化之后的DCG:其中IDCG是指idealDCG,也就是完美结果下的DCG。
通俗来解释,NDCG其实就是:一个推荐系统返回一些项并形成一个列表,我们想要计算这个列表有多好。
每一项都有一个相关的评分值,通常这些评分值是一个非负数,这就是gain(增益)。
此外,对于这些没有用户反馈的项,我们通常设置其增益为0。
现在,我们把这些分数相加,也就是CumulativeGain(累积增益)。
我们更愿意看那些位于列表前面的最相关的项,因此,在把这些分数相加之前,我们将每项除以一个递增的数(通常是该项位置的对数值),也就是折损值,并得到DCG。
在用户与用户之间,DCG没有直接的可比性,所以我们要对它们进行归一化处理。
最糟糕的情况是,当使用非负相关评分时DCG为0。
为了得到最好的,我们把测试集中所有的条目置放在理想的次序下,采取的是前K项并计算它们的DCG。
然后将原DCG除以理想状态下的DCG并得到NDCG,它是一个0到1之间的数。
混淆矩阵的计算方法有哪些
#准确率(Accuracy,ACC)。
最常用、最经典的评估指标之一,计算公式为:
$ACC=\frac{预测准确的样例数}{总预测数}$。
由此可见,准确率是类别无关的,衡量整个数据集的准确情况,即预测正确的样本所占的比例。
bytheway,有时人们也会用错误率(ErrorRate,ERR),与准确率定义相反,表示分类错误的样本所占的比例,计算公式为:
$ERR=1-ACC$
**存在问题**
在类别不平衡数据集中,ACC不能客观反映模型的能力。
比如在三分类中,样本数量分布为(9800,100,100),那么模型只要无脑将所有样例都预测为A类即可以有98%的准确率,然而事实是模型根本没有分辨ABC的能力。
因此下面引入精确率和召回率的概念。
#概念定义
介绍精确率和召回率之前,我们先来了解几个概念:

|名称|定义|
|------|------|
|TP(TruePositives,真阳性样本数) |被正确预测为正类别的样本个数|
|FP(FalsePositives,假阳性样本数) |被错误预测为正类别的样本个数|
|FN(FalseNegatives,假阴性样本数) |被错误预测为负类别的样本个数|
|TN(TrueNegatives,真阴性样本数) |被正常预测为负类别的样本个数|
注意:
*第一个字母代表预测是否正确,第二个字母代表预测结果。
GroundTruth(标签,数据的类别的真实情况,GT)则需要通过玩家组合这两个字母进行推理:预测正确则代表GT和预测结果一致,即TP的样本是正类别,TN的样本是负类别;反之FP的样本是负类别,FN的样本是正类别。
搞清楚这个对精确率和召回率的了解会更加容易。
*对于二分类而言,只要规定了正类别和负类别,这4个值是唯一的(负类别的TP等于正类别的TN,负类别的FP等于正类别的FN,负类别的FN等于正类别的FP,负类别的TN等于正类别的TP,因此对于二分类问题衡量正类别的指标就够了,因为两个类别是对等的)。
对于多分类而言,用**OneVSOthers**的思想,将其中一类看作正类别,其他类看作负类别,**则每个类别都有这4个值,即这4个值在多分类中是与类别强相关的,每个类别的这几个值都不一样。
**。
#混淆矩阵
混淆矩阵是所有分类算法模型评估的基础,它展示了模型预测结果和GT的对应关系。
|推理类别/真实类别|A|B|C|D|
|:----:|:----:|:----:|:----:|:----:|
|A|56|5|11|0|
|B|5|83|0|26|
|C|9|0|28|2|
|D|1|3|6|47|
其中矩阵所有元素之和为样本总数,每一行代表**预测为某类别的样本在真实类别中的分布**,每一列代表**某真实类别的样本在预测类别中的分布**。
以A类为例,第一行代表预测为A的有72个样本(即TP+FP,56+5+11+0),第一列表示真实类别为A的有71个样本(即TP+FN,56+5+9+1)。
其中TP为56,FP为16(行,5+11+0),FN为15(列,5+9+1),TN为195(即除第一行和第一列外所有的值之和)。

样本总数等于混淆矩阵所有元素之和,即282。
如果用符号E来表示$B\cupC\cupD$,那么对于A来说,混淆矩阵可以改写如下:
|推理类别/真实类别|A|E|
|:----:|:----:|:----:|
|A|56|16|
|E|15|195|
由此可见,对于二分类来说,混淆矩阵的值与TP等指标对应如下:
|推理类别/真实类别|Positives(正类别)|Negatives(负类别)|
|:----:|:----:|:----:|
|Positives(正类别)|TP|FP|
|Negatives(负类别)|FN|TN|
对应多分类,可以用不同颜色来对应TP等指标的区域,使可视化效果更好,更方便理解。后续再更新。
#精确率(Precision,$P$)
**对于某一类别而言**,预测为该类别样本中确实为该类别样本的比例,计算公式为:
$P=\frac{TP}{TP+FP}$。
以A、E的混淆矩阵为例:$P_A=\frac{56}{56+16}=0.78,P_E=\frac{195}{15+195}=0.93$。
以ABCD的混淆矩阵为例:$P_A=0.78,P_B=\frac{83}{5+83+0+26}=0.73,P_C=\frac{28}{9+0+28+2}=0.72,P_D=\frac{47}{1+3+6+47}=0.83$。
可以观察到,精确率的分母是混淆矩阵的行和,分子在对角线上。
#召回率(Recall,$R$)
**对于某一类别而言**,在某类别所有的真实样本中,被预测(找出来,召回)为该类别的样本数量的比例,计算公式为:
$R=\frac{TP}{TP+FN}$。
以A、E的混淆矩阵为例:$R_A=\frac{56}{56+15}=0.79,R_E=\frac{195}{16+195}=0.92$。
以ABCD的混淆矩阵为例:$R_A=0.79,R_B=\frac{83}{5+83+0+3}=0.91,R_C=\frac{28}{11+0+28+6}=0.62,R_D=\frac{47}{0+26+2+47}=0.63$。
可以观察到,召回率的分母是混淆矩阵的列和,分子在对角线上。
#F1
刚才提到,用ACC衡量模型的能力并不准确,因此要同时衡量精确率和召回率,遗憾的是,**一个模型的精确率和召回率往往是此消彼长的**。
用西瓜书上的解释就是:挑西瓜的时候,如果希望将好瓜尽可能多地选出来(提高召回率),则可以通过增加选瓜的数量来实现(),如果将所有西瓜都选上(),那么所有的好瓜也必然被选上了,但是这样的策略明显精确率较低;若希望选出的瓜中好瓜比例可能高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,使得召回率较低。
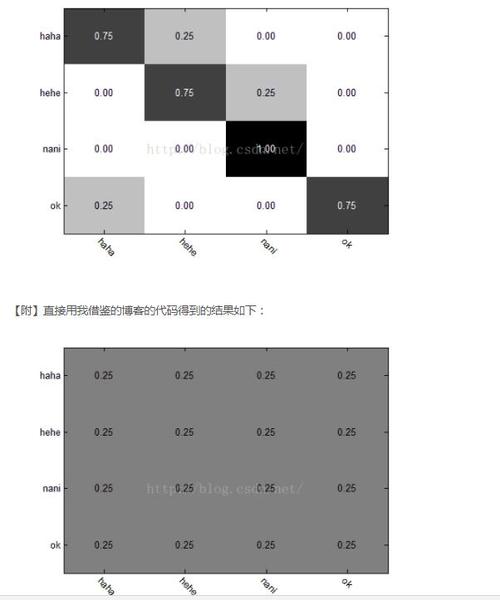
通常只有在一些简单任务中,才可能使得召回率和精确率都很高。
因此我们引入F1来评价精确率和召回率的综合效果,F1是这两个值的调和平均(harmonicmean,与算数平均$\frac{P+R}{2}$和几何平均$\sqrt{P*R}$相比,调和平均更重视较小值),定义如下:
$\frac{1}{F1}=\frac{1}{2}*(\frac{1}{P}+\frac{1}{R})$。
化简得:
$F1=\frac{2*P*R}{P+R}$。
在一些应用中,对精确率和召回率的重视程度有所不同。
例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容的确是用户感兴趣的,此时精确率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时召回率更重要。
$F1$的一般形式————$F_\beta$,能让我们表达出对精确率和召回率的不同偏好,它定义为:
$F_\beta=\frac{(1+\beta^2)*P*R}{(\beta^2*P)+R}$。
其中$\beta>0$度量了召回率对精确率的相对重要性。
$\beta=1$时退化为标准$F1$;$\beta>1$时召回率有更大影响;$\beta<1$时精确率有更大影响。
以AE的混淆矩阵为例:
$F1_A=\frac{2*P_A*R_A}{P_A+R_A}=\frac{2*0.78*0.93}{0.78+0.93}=0.85$。
$F1_E=\frac{2*P_E*R_E}{P_E+R_E}=\frac{2*0.93*0.92}{0.93+0.92}=0.92$。
以ABCD的混淆矩阵为例:
$F1_A=0.85$
$F1_B=\frac{2*P_B*R_B}{P_B+R_B}=\frac{2*0.73*0.91}{0.73+0.91}=0.81$。
$F1_C=\frac{2*P_C*R_C}{P_C+R_C}=\frac{2*0.72*0.62}{0.72+0.62}=0.67$。
$F1_D=\frac{2*P_D*R_D}{P_D+R_D}=\frac{2*0.83*0.63}{0.83+0.63}=0.72$。
#多分类
以上指标除了准确率,其他指标都是类别相关的。要对模型做出总体评价,就需要算出所有类别综合之后的总体指标。求总体指标的方法有两种:宏平均(MacroAverage)和微平均(MicroAverage)。
**宏平均**
计算各个类对应的指标的算术平均
例,$F1_{macro}=\frac{F1_A+F1_B+F1_C+F1_D}{4}=\frac{0.85+0.81+0.67+0.72}{4}=0.7625$。
所谓宏,就是从更宏观的角度去平均,即粒度是在类以上的。
**微平均**
先平均每个类别的TP、FP、TN、FN,再计算他们的衍生指标。
例,
$TP_{micro}=\frac{TP_A+TP_B+TP_C+TP_D}{4}=\frac{56+83+28+47}{4}=53.5$。
$FP_{micro}=\frac{FP_A+FP_B+FP_C+FP_D}{4}=\frac{16+31+11+10}{4}=17$。
$FN_{micro}=\frac{FN_A+FN_B+FN_C+FN_D}{4}=\frac{15+8+17+28}{4}=17$。
$TN_{micro}=\frac{TN_A+TN_B+TN_C+FN_D}{4}=\frac{195+160+226+197}{4}=194.5$。
$P_{micro}=\frac{TP_{micro}}{TP_{micro}+FP_{micro}}=\frac{53.5}{53.5+17}=0.7589$。
$R_{micro}=\frac{TP_{micro}}{TP_{micro}+FN_{micro}}=\frac{53.5}{53.5+17}=0.7589$。
$F1_{micro}=\frac{2*P_{micro}*R_{micro}}{P_{micro}+R_{micro}}=\frac{2*0.7589*0.7589}{0.7589+0.7589}=0.7589$。
1.《西瓜书》
2.《ModelArts人工智能应用开发指南》。
如有错误,欢迎指出。下一期继续探讨ROC曲线、AUC曲线和PR曲线
")
")
")
")




还没有评论,来说两句吧...