

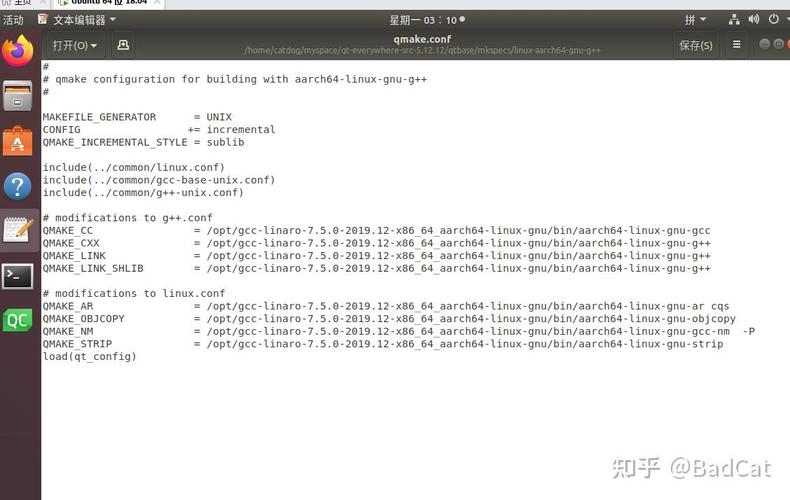
SDCC(SmallDeviceCCompiler)是一个优化的ANSI-C交叉编译器,目标CPU为基于Intel8051,Maxim80DS390,ZilogZ80和Motorola68HC08的单片机。
SDCC同时带有一个源代码级调试工具SDCDB,使用的是Daniel'ss51仿真器当前版本。SDCC是由SandeepDutta所写的,并依据GPLlicense发行。
sdcc的特点:
1、SDCC的sdas和sdld是基于ASXXXX的交叉编译工具和链接工具,他们都是免费开源的软件,依据GNUGeneralPublicLicense(GPL)发布。
2、有针对特定MCU的编程语言扩展,可以高效的使用基本的硬件资源。
3、有大量的标准优化,如全局字表达式削减,循环优化(无任何操作的循环优化,归纳变量循环优化,逆循环优化),常量合并的传播,复制传播,死代码删除,'switch'语句的转移表优化。
4、针对特定MCU的优化,包括全局寄存器分配算法。
5、特定MCU后端适应能力,能够很好的适配其他的8位的MCU。
交叉编译出现和流行是和嵌入式系统的广泛发展同步的。常用的计算机软件,都需要通过编译的方式,把使用高级计算机语言编写的代码(比如C代码)编译(compile)成计算机可以识别和执行的二进制代码。
比如,在Windows平台上,可使用VisualC++开发环境,编写程序并编译成可执行程序。
这种方式下,我们使用PC平台上的Windows工具开发针对Windows本身的可执行程序,这种编译过程称为nativecompilation,中文可理解为本机编译。
然而,在进行嵌入式系统的开发时,运行程序的目标平台通常具有有限的存储空间和运算能力,比如常见的ARM平台,其一般的静态存储空间大概是16到32MB,而CPU的主频大概在100MHz到500MHz之间。
这种情况下,在ARM平台上进行本机编译就不太可能了,这是因为一般的编译工具链(compilationtoolchain)需要很大的存储空间,并需要很强的CPU运算能力。
为了解决这个问题,交叉编译工具就应运而生了。通过交叉编译工具,我们就可以在CPU能力很强、存储空间足够的主机平台上(比如PC上)编译出针对其他平台的可执行程序。
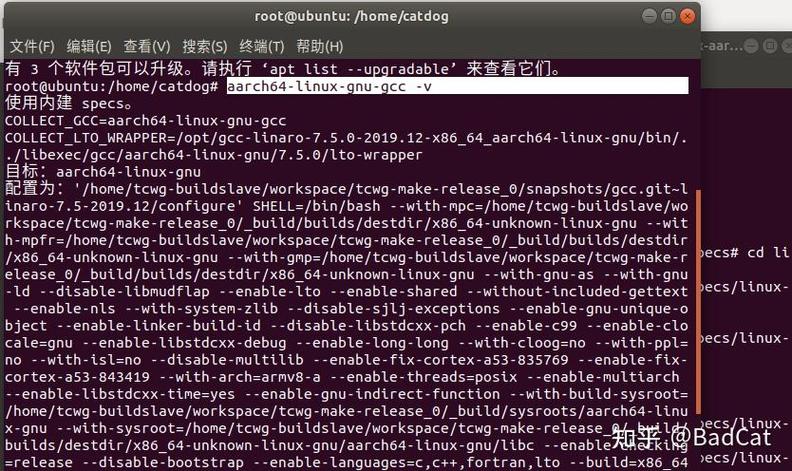
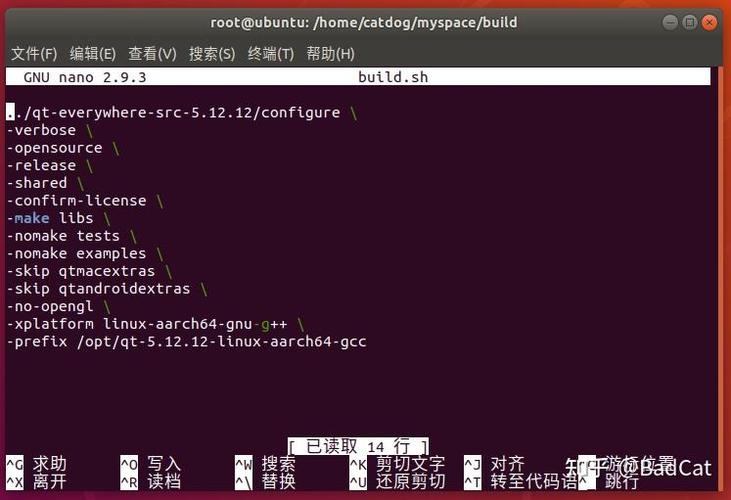
要进行交叉编译,要在主机平台上安装对应的交叉编译工具链(crosscompilationtoolchain),然后用这个交叉编译工具链编译我们的源代码,最终生成可在目标平台上运行的代码。
交叉编译器有哪些类型
20世纪50年代,IBM的JohnBackus带领一个研究小组对FORTRAN语言及其编译器进行开发。
但由于当时人们对编译理论了解不多,开发工作变得既复杂又艰苦。
与此同时,NoamChomsky开始了他对自然语言结构的研究。
他的发现最终使得编译器的结构异常简单,甚至还带有了一些自动化。
Chomsky的研究导致了根据语言文法的难易程度以及识别它们所需要的算法来对语言分类。
正如所称的Chomsky架构(ChomskyHierarchy),它包括了文法的四个层次:0型文法、1型文法、2型文法和3型文法,且其中的每一个都是其前者的特殊情况。
2型文法(或上下文无关文法)被证明是程序设计语言中最有用的,而且今天它已代表着程序设计语言结构的标准方式。
分析问题(parsingproblem,用于上下文无关文法识别的有效算法)的研究是在60年代和70年代,它相当完善的解决了这个问题。
它已是编译原理中的一个标准部分。
有限状态自动机(FiniteAutomation)和正则表达式(RegularExpression)同上下文无关文法紧密相关,它们与Chomsky的3型文法相对应。
对它们的研究与Chomsky的研究几乎同时开始,并且引出了表示程序设计语言的单词的符号方式。
人们接着又深化了生成有效目标代码的方法,这就是最初的编译器,它们被一直使用至今。
人们通常将其称为优化技术(OptimizationTechnique),但因其从未真正地得到过被优化了的目标代码而仅仅改进了它的有效性,因此实际上应称作代码改进技术(CodeImprovementTechnique)。
当分析问题变得好懂起来时,人们就在开发程序上花费了很大的功夫来研究这一部分的编译器自动构造。
这些程序最初被称为编译器的编译器(Compiler-compiler),但更确切地应称为分析程序生成器(ParserGenerator),这是因为它们仅仅能够自动处理编译的一部分。
这些程序中最著名的是Yacc(YetAnotherCompiler-compiler),它是由SteveJohnson在1975年为Unix系统编写的。
类似的,有限状态自动机的研究也发展了一种称为扫描程序生成器(ScannerGenerator)的工具,Lex(与Yacc同时,由MikeLesk为Unix系统开发)是这其中的佼佼者。
在20世纪70年代后期和80年代早期,大量的项目都贯注于编译器其它部分的生成自动化,这其中就包括了代码生成。这些尝试并未取得多少成功,这大概是因为操作太复杂而人们又对其不甚了解。
编译器设计最近的发展包括:首先,编译器包括了更加复杂算法的应用程序它用于推断或简化程序中的信息;这又与更为复杂的程序设计语言的发展结合在一起。
其中典型的有用于函数语言编译的Hindley-Milner类型检查的统一算法。
其次,编译器已越来越成为基于窗口的交互开发环境(InteractiveDevelopmentEnvironment,IDE)的一部分,它包括了编辑器、连接程序、调试程序以及项目管理程序。
这样的IDE标准并没有多少,但是对标准的窗口环境进行开发已成为方向。
另一方面,尽管在编译原理领域进行了大量的研究,但是基本的编译器设计原理在近20年中都没有多大的改变,它正迅速地成为计算机科学课程中的中心环节。
在20世纪90年代,作为GNU项目或其它开放源代码项目标一部分,许多免费编译器和编译器开发工具被开发出来。
这些工具可用来编译所有的计算机程序语言。
它们中的一些项目被认为是高质量的,而且对现代编译理论感兴趣的人可以很容易的得到它们的免费源代码。
大约在1999年,SGI公布了他们的一个工业化的并行化优化编译器Pro64的源代码,后被全世界多个编译器研究小组用来做研究平台,并命名为Open64。
Open64的设计结构好,分析优化全面,是编译器高级研究的理想平台。








还没有评论,来说两句吧...