

自己之前一直没搞清楚这两个交叉编译器到底有什么问题,特意google一番,总结如下,希望能帮到道上和我有同样困惑的兄弟…..
一.什么是ABI和EABI
1)ABI:二进制应用程序接口(ApplicationBinaryInterface(ABI)fortheARMArchitecture)。
在计算机中,应用二进制接口描述了应用程序(或者其他类型)和操作系统之间或其他应用程序的低级接口.
ABI涵盖了各种细节,如:
数据类型的大小、布局和对齐;
调用约定(控制着函数的参数如何传送以及如何接受返回值),例如,是所有的参数都通过栈传递,还是部分参数通过寄存器传递;哪个寄存器用于哪个函数参数;通过栈传递的第一个函数参数是最先push到栈上还是最后;
系统调用的编码和一个应用如何向操作系统进行系统调用;
以及在一个完整的操作系统ABI中,目标文件的二进制格式、程序库等等。
一个完整的ABI,像Intel二进制兼容标准(iBCS),允许支持它的操作系统上的程序不经修改在其他支持此ABI的操作体统上运行。
ABI不同于应用程序接口(API),API定义了源代码和库之间的接口,因此同样的代码可以在支持这个API的任何系统中编译,ABI允许编译好的目标代码在使用兼容ABI的系统中无需改动就能运行。
2)EABI:嵌入式ABI
嵌入式应用二进制接口指定了文件格式、数据类型、寄存器使用、堆积组织优化和在一个嵌入式软件中的参数的标准约定。
开发者使用自己的汇编语言也可以使用EABI作为与兼容的编译器生成的汇编语言的接口。
支持EABI的编译器创建的目标文件可以和使用类似编译器产生的代码兼容,这样允许开发者链接一个由不同编译器产生的库。
EABI与关于通用计算机的ABI的主要区别是应用程序代码中允许使用特权指令,不需要动态链接(有时是禁止的),和更紧凑的堆栈帧组织用来节省内存。广泛使用EABI的有PowerPC和ARM.
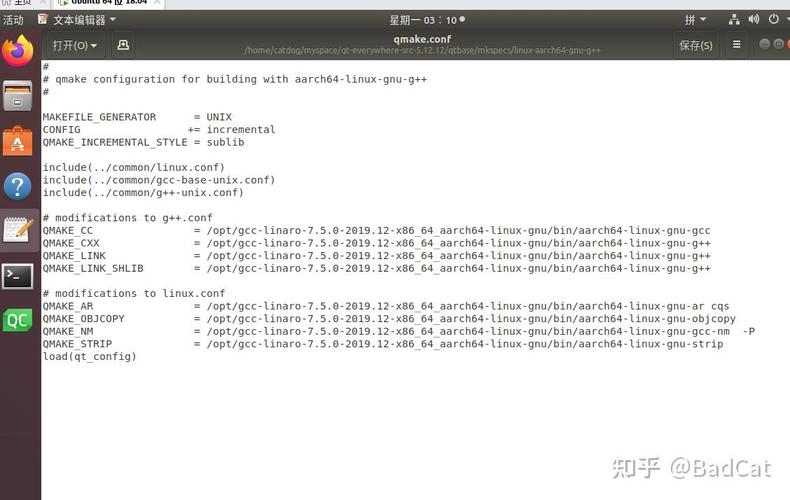
二.gnueabi相关的两个交叉编译器:gnueabi和gnueabihf。
在debian源里这两个交叉编译器的定义如下:。
gcc-arm-linux-gnueabi–TheGNUCcompilerforarmelarchitecture。
gcc-arm-linux-gnueabihf–TheGNUCcompilerforarmhfarchitecture。
可见这两个交叉编译器适用于armel和armhf两个不同的架构,armel和armhf这两种架构在对待浮点运算采取了不同的策略(有fpu的arm才能支持这两种浮点运算策略)。
其实这两个交叉编译器只不过是gcc的选项-mfloat-abi的默认值不同.gcc的选项-mfloat-abi有三种值soft,softfp,hard(其中后两者都要求arm里有fpu浮点运算单元,soft与后两者是兼容的,但softfp和hard两种模式互不兼容):
soft:不用fpu进行浮点计算,即使有fpu浮点运算单元也不用,而是使用软件模式。
softfp:armel架构(对应的编译器为gcc-arm-linux-gnueabi)采用的默认值,用fpu计算,但是传参数用普通寄存器传,这样中断的时候,只需要保存普通寄存器,中断负荷小,但是参数需要转换成浮点的再计算。
hard:armhf架构(对应的编译器gcc-arm-linux-gnueabihf)采用的默认值,用fpu计算,传参数也用fpu中的浮点寄存器传,省去了转换,性能最好,但是中断负荷高。
把以下测试使用的c文件内容保存成mfloat.c:
#include<stdio.h>。
intmain(void)
{
doublea,b,c;
a=23.543;
b=323.234;
c=b/a;
printf(“the13/2=%f\n”,c);。
printf(“helloworld!\n”);。
return0;
}
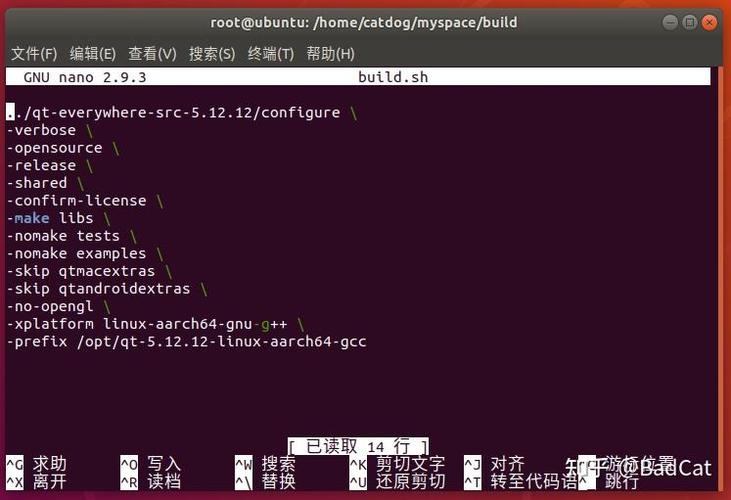
1)使用arm-linux-gnueabihf-gcc编译,使用“-v”选项以获取更详细的信息:。
#arm-linux-gnueabihf-gcc-vmfloat.c。
COLLECT_GCC_OPTIONS=’-v’‘-march=armv7-a’‘-mfloat-abi=hard’‘-mfpu=vfpv3-d16′‘-mthumb’。
-mfloat-abi=hard,可看出使用hard硬件浮点模式。
2)使用arm-linux-gnueabi-gcc编译:。
#arm-linux-gnueabi-gcc-vmfloat.c。
COLLECT_GCC_OPTIONS=’-v’‘-march=armv7-a’‘-mfloat-abi=softfp’‘-mfpu=vfpv3-d16′‘-mthumb’。
-mfloat-abi=softfp,可看出使用softfp模式。
三.拓展阅读
下文阐述了ARM代码编译时的软浮点(soft-float)和硬浮点(hard-float)的编译以及链接实现时的不同。
从VFP浮点单元的引入到软浮点(soft-float)和硬浮点(hard-float)的概念。
VFP(vectorfloating-point)。
从ARMv5开始,就有可选的VectorFloatingPoint(VFP)模块,当然最新的如Cortex-A8,Cortex-A9和Cortex-A5可以配置成不带VFP的模式供芯片厂商选择。
VFP经过若干年的发展,有VFPv2(一些ARM9/ARM11)、VFPv3-D16(只使用16个浮点寄存器,默认为32个)和VFPv3+NEON(如大多数的Cortex-A8芯片)。
对于包含NEON的ARM芯片,NEON一般和VFP公用寄存器。
硬浮点Hard-float
编译器将代码直接编译成发射给硬件浮点协处理器(浮点运算单元FPU)去执行。FPU通常有一套额外的寄存器来完成浮点参数传递和运算。
使用实际的硬件浮点运算单元FPU当然会带来性能的提升。因为往往一个浮点的函数调用需要几个或者几十个时钟周期。
软浮点Soft-float
编译器把浮点运算转换成浮点运算的函数调用和库函数调用,没有FPU的指令调用,也没有浮点寄存器的参数传递。浮点参数的传递也是通过ARM寄存器或者堆栈完成。
现在的Linux系统默认编译选择使用hard-float,即使系统没有任何浮点处理器单元,这就会产生非法指令和异常。因而一般的系统镜像都采用软浮点以兼容没有VFP的处理器。
armelABI和armhfABI
在armel中,关于浮点数计算的约定有三种。以gcc为例,对应的-mfloat-abi参数值有三个:soft,softfp,hard。
soft是指所有浮点运算全部在软件层实现,效率当然不高,会存在不必要的浮点到整数、整数到浮点的转换,只适合于早期没有浮点计算单元的ARM处理器;
softfp是目前armel的默认设置,它将浮点计算交给FPU处理,但函数参数的传递使用通用的整型寄存器而不是FPU寄存器;
hard则使用FPU浮点寄存器将函数参数传递给FPU处理。
需要注意的是,在兼容性上,soft与后两者是兼容的,但softfp和hard两种模式不兼容。
默认情况下,armel使用softfp,因此将hard模式的armel单独作为一个abi,称之为armhf。
而使用hard模式,在每次浮点相关函数调用时,平均能节省20个CPU周期。对ARM这样每个周期都很重要的体系结构来说,这样的提升无疑是巨大的。
在完全不改变源码和配置的情况下,在一些应用程序上,使用armhf能得到20%——25%的性能提升。对一些严重依赖于浮点运算的程序,更是可以达到300%的性能提升。
Soft-float和hard-float的编译选项。
在CodeSourcerygcc的编译参数上,使用-mfloat-abi=name来指定浮点运算处理方式。-mfpu=name来指定浮点协处理的类型。
可选类型如fpa,fpe2,fpe3,maverick,vfp,vfpv3,vfpv3-fp16,vfpv3-d16,vfpv3-d16-fp16,vfpv3xd,vfpv3xd-fp16,neon,neon-fp16,vfpv4,vfpv4-d16,fpv4-sp-d16,neon-vfpv4等。
使用-mfloat-abi=hard(等价于-mhard-float)-mfpu=vfp来选择编译成硬浮点。
使用-mfloat-abi=softfp就能兼容带VFP的硬件以及soft-float的软件实现,运行时的连接器ld.so会在执行浮点运算时对于运算单元的选择,。
是直接的硬件调用还是库函数调用,是执行/lib还是/lib/vfp下的libm。-mfloat-abi=soft(等价于-msoft-float)直接调用软浮点实现库。
在ARMRVCT工具链下,定义fpu模式:
–fpusoftvfp
–fpusoftvfp+vfpv2
–fpusoftvfp+vfpv3
–fpusoftvfp+vfpv_fp16。
–fpusoftvfp+vfpv_d16
–fpusoftvfp+vfpv_d16_fp16.
定义浮点运算类型
–fpmodeieee_full:所有单精度float和双精度double的精度都要和IEEE标准一致,具体的模式可以在运行时动态指定;
–fpmodeieee_fixed:舍入到最接近的实现的IEEE标准,不带不精确的异常;
–fpmodeieee_no_fenv:舍入到最接近的实现的IEEE标准,不带异常;
–fpmodestd:非规格数flush到0、舍入到最接近的实现的IEEE标准,不带异常;
–fpmodefast:更积极的优化,可能会有一点精度损失。
交叉编译器的作用是
深入了解计算机世界的神秘语言,让我们一探究竟——何为交叉编译。本文将深入剖析编译的奥秘,以及它如何在不同架构间搭建桥梁。
一、编译:从基础到复杂
想象一下,你对计算机说出"helloworld",仿佛在与一个不懂人类语言的机器交谈。

其实,是编译器将你的指令转化为它能理解的二进制代码。
计算机中的每个字符,都被转化成了0101的序列,这是电子元器件如晶体管能识别的语言。
这些元器件通过电压和电流的变化,模拟出数字的逻辑运算,这就是计算机计算的底层逻辑。

晶体管中的mosfet,如同电子世界的翻译官,输入电压变化,输出电压也随之响应。
尽管电压的精确控制不易,但高低电平的切换却相对容易,这就构成了计算机中的二进制状态。
每个不同的状态,都对应着特定的指令,不同的CPU架构,如x86、arm,其高低电平表示方式和指令集都有所差异,导致相同代码在不同平台上表现各异。
二、编译的挑战与解决方案:交叉编译
面对不同架构间的差异,编译者面临的任务就像美国打工人和中国打工人在语言上的沟通。
我们希望软件能在各种平台无缝运行,这就催生了交叉编译的概念。
它允许你在一个平台(如x86)上编译出可在另一个平台(如arm)上执行的代码,就像美国人用英文作答,通过翻译软件转化为中文让中国人理解。
然而,这并不意味着编译后的代码能在原平台运行,就像美国人用中文考试,结果对其他美国人和他自己来说都是陌生的。
但对目标平台来说,它能理解并执行。
这就是跨平台编译器的神奇之处,它在源代码和目标平台之间建立了一座桥梁。
三、x86Linux下编译armLinux的编译器探索。
要掌握x86Linux编译armLinux的编译器,如gnueabi、none-eabi等,我们需要深入理解它们的特性和差异。
这些编译器的选择和配置对于确保代码在不同架构间正确运行至关重要。
通过学习和实践,我们可以解锁跨平台开发的无限可能。
在探索编译世界的道路上,我们不断学习,不断适应,就像在炼丹与人工智能的领域,我在北京的工作经历让我对这些技术有了更深的理解。让我们一起在这个领域中成长,分享知识,共同进步。








还没有评论,来说两句吧...