

计算机显示使用硬件加速会快些,但有时会带来负面效果,如会在投影仪或截图时发现显示区是黑的,这时就要关闭硬件加速(硬件加速反方向操作)。
硬件加速(Hardwareacceleration)就是利用硬件模块来替代软件算法以充分利用硬件所固有的快速特性。硬件加速通常比软件算法的效率要高。
区别:功耗高了一部分,性能发生了一部分变化,调节硬件加速设置,增加、减少或关闭,对电脑本身没有什么危害,仅仅只是对电脑的系统和程序运行产生了性能上的变化。
硬件加速是用显卡的GPU解码视频,几乎不占用CPU,在播放高清视频时如果你的CPU不给力就会卡,不卡也会占用率很高,开启硬件加速就是让显卡分担了CPU的解码工作,所以你可以再开别的程序也不会卡。
硬件加速技术:
中央处理器的结构使得它能够在短时间内完成各种各样不同的指令。它能够处理什么指令主要由软件限制。但是由于中央处理器的结构有些重复任务无法非常有效和迅速地被处理。由于软件的原因处理器优化的可能性有限。
通过使用专门为这样的重复任务设计的特殊硬件元件(芯片或者处理器)可以解决这个问题。
这些特殊硬件元件不必像中央处理器那样灵活,因此它们的硬件设计就已经顾及了优化处理这些特殊问题的需要,这样一来中央处理器有时间去处理其它任务。
有些任务能够通过把它们分解为上千小任务非常有效地被解决。比如对一定的频率带做傅里叶变换或者渲染一小块图像。这些小任务可以互相之间不相关地平行计算。
通过大量平行计算,即适用大量平行运行的小处理器来处理这些特殊任务总的计算速度可以大大提高。在许多情况下计算速度随平行处理器的数量线性提高。比如在GeForce200图像卡上192个流处理器平行运行。
从有效利用能源的角度出发这样的平行计算也有意义。能源使用随平行处理器的数量线性提高,而随处理器频率成平方比提高。因此通过平行运算处理器的频率不必过高,使用的能量也比较少。
硬件加速gpu是什么
硬件加速GPU计划其实是Hardware-acceleratedGPUscheduling。
这样一看这俩描述就很容易让人产生误解,其实他不是加速gpu,只是优化了gpu硬件的调度算法和策略使得性能进一步提高。
要说到GPU调度管理,我们就先要了解一下WDDMGPU调度器是什么。
WDDMGPU调度器与命令缓冲队列
从NT6开始,微软给Windows引入了一套新的显示驱动模型,也就是我们现在所熟知的WindowsDisplayDriverModel,简称WDDM。
在WDDM出现之前,应用程序可以直接把任务提交到GPU,当时系统只有一个全局的任务队列,严格按照先到先执行的原则进行任务的调度。
鉴于当时用到GPU的场景基本上就是全屏游戏或者专业用途的渲染什么的,这种方案也没出什么问题,被沿用了很多年。
现在很多程序都会调用GPU
到了应用程序开始普遍利用GPU加速的年代,比如说Windows要直接用GPU加速整个UI界面的渲染了,那么再用这个全局任务队列就会有问题,比如渲染系统界面的任务前面排了一个其他程序提交的任务,那么GPU会先处理掉那个任务再回头来处理系统的需求,这会造成整个系统UI的卡顿。
为了妥善地安排GPU工作的优先级,势必需要一个新的任务调度器,由它负责安排GPU任务的工作优先级。
那么WDDM就引入了那么一个任务调度器,它以高优先级线程的形式一直运行在CPU上,负责协调、优先处理和调度各种应用程序提交的工作。
从Vista上面的WDDM1.0到Windows10Version2004的WDDM2.7,官方一直都在加强这个调度器的功能。
但这种管理方式存在有一定的限制,主要体现在提交会有额外开销和任务达到GPU有一定的延迟时间,不过这些限制在实际中都被传统图形应用的渲染缓冲队列给掩盖了。
缓冲用来存放提前准备好的渲染命令等等内容,在GPU渲染当前帧的时候,CPU已经在准备下一帧、下下帧乃至之后的更多帧数了。
这种方式能够保证CPU与GPU之间的良好执行并行性,也可降低整体的性能开销,是现在很常见的GPU调用方式。
同时为了降低频率提交渲染命令带来的额外性能开销,一般应用程序会提前准备好多帧的内容一起发送到队列中。
这里产生了问题,缓冲的帧数越多,用户能够感受到的延迟越高。
题外话,NVIDIA和AMD两家在去年都已经在驱动层面提供了对缓冲队列深度的控制,通过降低缓冲队列的帧数来实现降低延迟这一目的。
但如果想减少缓冲队列的深度来降低延迟,又会造成提交开销增加,影响到性能。
这两者之间是一个权衡关系,程序可能以更高的频率每次提交更少的帧数来降低延迟,又可能以较低的频率每次提交更多的帧数来减少额外的调度、提交开销。
所以,微软决定修改其显示驱动模型的基础架构,引入了“硬件加速GPU计划”。
把任务调度交给专用硬件
Windows10Version2004中引入的新选项就是允许系统将绝大多数的调度任务交由GPU专有的硬件调度器去做,Windows将继续控制程序调用GPU的优先级,但高频任务将会交由GPU的调度处理器进行管理,它负责各种GPU引擎的量子管理和上下文切换。
在NVIDIA的官方说法中,新的选项就是允许GPU直接管理它自有的内存,也就是显存,在此之前,显存是交给系统来管理的。
要启用这个新调度方式有两个先决条件,一个是需要硬件支持:它需要GPU自身有专有的处理调度任务的硬件模块,另一个是驱动支持:系统需要一个符合WDDM2.7标准的显示驱动。
当你的驱动和硬件都支持时,系统设置里才会出现这一选项。
另外,引入新的调度方式对驱动模型有一个重大且根本性的改变,在某些时候、某些场景下它可能会产生不可知的效果,因此微软将其作为一个实验性的选项,默认情况下是关闭掉的。
目前开发团队还在比较两种调度器之间的性能差异,同时也在监控新调度器的可靠性,未来这个选项可能会在支持的硬件上变为默认开启状态。
目前支持这一特性的GPU有NVIDIA的PascalGPU和TuringGPU、AMD的RDNAGPU,Intel那边的情况不明。
实际测试:对高端平台影响不大
好了,说了那么多,我们还是来看看这项功能在实际中的表现吧,我们找来了Tom'sHardware和Wccftech两家媒体的测试数据(以下图片来自于Tom'sHardware和Wccftech)。
Tom'sHardware这边使用了三套测试平台,分别是Corei9-9900K+RTX2080Ti、Ryzen93900X+RTX2080Ti和Corei9-9900K+GTX1050。
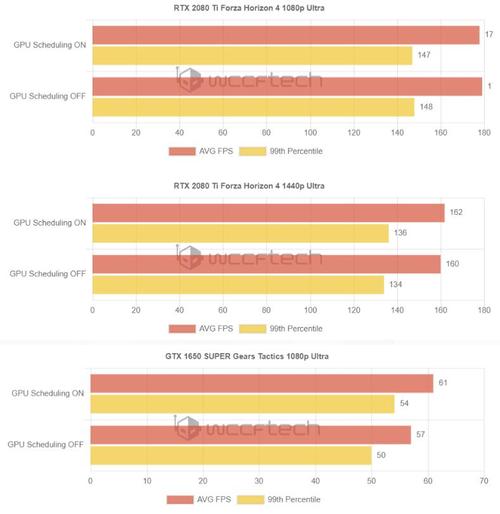
从五款游戏的测试结果来看,基本上没有用户可感知的区别。
Wccftech选择了Corei9-9900K+RTX2080Ti/GTX1650SUPER这样两套平台,在RTX2080Ti上面启用硬件调度的性能变化并不明显,但是在GTX1650SUPER这样一张主流级显卡上面则是出现了明显的提升。
其原因,如果按照NVIDIA方面的说法来解释,那就是由GPU直接管理显存在效率上带来了一定的提升。

也许,这项功能会为很多主流级平台带来可观的免费性能增幅,而对高端平台来说,影响是微乎其微的。
总结:仍需时日完善的好技术
所以,“硬件加速GPU计划”实质上是一项对Windows图形架构影响较大的新技术,它需要新硬件和新驱动的支持才能够实现,能够为平台带来一定的性能提升。
但目前它仍然处于测试状态,GPU厂对它的支持仍然算是刚刚可以用的状态,还需要官方进一步的优化和完善它。
这也是微软为次世代图形应用对系统做出的改变,为了尽可能的降低延迟,让系统跟上时代的发展。
它是一项好技术,但仍然还有很长的一段路要走。








还没有评论,来说两句吧...